- トップページ
- システムアーキテクト
- 平成26年度秋季問題
- 平成26年度秋季解答・解説
平成26年度秋季解答
問題11
論理型プログラミングにおいて、命題の証明を行うための基本的な操作はどれか。
| ア | オーバーライド |
| イ | オーバーロード |
| ウ | メッセージパッシング |
| エ | ユニフィケーション |
解答:エ
<解説>
| ア | × | オーバーライドとは、オブジェクト指向プログラミングにおいてオーバーライド (override)とは、スーパークラスで定義されたメソッドをサブクラスで定義しなおし、動作を上書きすることである。 |
| イ | × | オーバーロードとは、プログラミング言語において関数や演算子やメソッドの同一名や同一の演算子記号について複数定義し、利用時にプログラムの文脈に応じて選択することで複数の動作を行わせる仕組みである。 |
| ウ | × | メッセージパッシングとは、あるオブジェクトが他のオブジェクトにメソッドの実行を依頼することである。 |
| エ | ○ | ユニフィケーションとは、既存の事実と規則を組み合わせて、新たな命題を証明する操作である。単一化(ユニフィケーション)の考え方は Prolog に代表される論理プログラミングの根底を支える重要な概念である。 |
問題12
開発ライフサイクルモデルとして、ウォータフォールモデル、進化的モデル、スパイラルモデルの三つを考える。 ソフトウェア保守は、どのモデルを採用したときに必要か。
| ア | ウォータフォールモデルだけ |
| イ | ウォータフォールモデルと進化的モデルだけ |
| ウ | ウォータフォールモデルとスパイラルモデルだけ |
| エ | ウォータフォールモデル、進化的モデル、スパイラルモデルの全て |
解答:エ
<解説>
- ウォータフォールモデル
- システム全体を一括して管理し、分析・設計・実装・テスト・運用をこの順に行っていく(実際はもう少し細かく分ける)。各工程が完了する際に、前の工程への逆戻りが起こらないよう、綿密なチェックを行う。
- 進化的モデル
- 要求を最初に明確に定義することが難しい場合に適用されるモデル。部分的に定義された要求から開発を開始し、後続する開発単位ごとに毎回要求を洗練し、本当に求めている要求に近づけていく。
- スパイラルモデル
- システムの一部分について設計・実装を行い、仮組みのプログラムを元に顧客からのフィードバックやインターフェースの検討などを経て、さらに設計・実装を繰り返していく手法のこと。
どのような開発ライフサイクルモデルを採用しようとも,ソフトウェア保守は必要である。したがって、エが正解である。
問題13
ユースケース駆動開発の利点はどれか。
| ア | 開発を反復するので、新しい要求やビジネス目標の変化に柔軟に対応しやすい。 |
| イ | 開発を反復するので、リスクが高い部分に対して初期段階で対処しやすく、プロジェクト全体のリスクを減らすことができる。 |
| ウ | 基本となるアーキテクチャをプロジェクトの初期に決定するので、コンポーネントを再現しやすくなる。 |
| エ | ひとまとまりの要件を単位として設計からテストまでを実施するので、要件ごとに開発状況が把握できる。 |
解答:エ
<解説>
ユースケース駆動開発は、ユースケースごとに開発作業を進める開発モデルである。ユースケースごとに設計からテストまでを実施するので要件ごとに開発状況を把握できる。
| ア | × | アジャイル開発の利点である。 |
| イ | × | スパイラルモデルの利点である。 |
| ウ | × | アーキテクチャ中心設計の利点である。 |
| エ | ○ | ユースケース駆動開発の利点である。 |
問題14
投資効果を現在価値法で評価するとき、最も投資効果の大きい(又は損失の小さい)シナリオはどれか。 ここで、期間は3年間、割引率は5%とし、各シナリオのキャッシュフローは表のとおりとする。
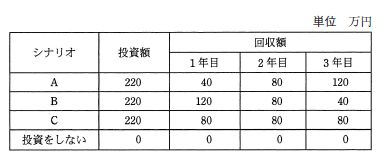
| ア | A |
| イ | B |
| ウ | C |
| エ | 投資をしないしない |
解答:イ
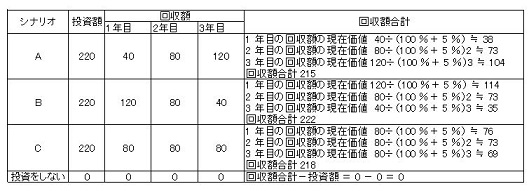
<解説>
次のようになり、イが最も投資効果の大きい(又は損失の小さい)シナリオとなる。
問題15
情報システムの全体計画立案のためにE-Rモデルを用いて会社のデータモデルを作成する手順はどれか。
| ア | 管理層の業務から機能を抽出し、機能をエンティティとする。 次に、機能の相互関係に基づいてリレーションシップを定義する。 さらに、会社の帳票類を調査して整理し、正規化された項目に基づいて属性を定義し、全社のデータモデルとする。 |
| イ | 企業の全体像を把握するため、基本的なエンティティだけを抽出し、それらの相互間のリレーションシップを含めて、鳥瞰かん図を作成する。 次にエンティティを詳細化し、すべてのリレーションシップを明確にしたものを全社のデータモデルとする。 |
| ウ | 業務層の現状システムを分析し、エンティティとリレーションシップを抽出する。 それぞれについて適切な属性を定め、これらを基にE-R図を作成し、それを抽象化して、全社のデータモデルを作成する。 |
| エ | 全社のデータとその処理過程を分析し、重要な処理を行っている業務を基本エンティティとする。 次に、基本エンティティ相互のデータの流れをリレーションシップとしてとらえ、適切な識別名を与える。 さらに、基本エンティティと関係あるデータを属性とし、全社のデータモデルを作成する。 |
解答:イ
<解説>
| ア | × | E-R モデルは,業務から抽出した機能に着目して作成するものではなく、必要なデータに着目する。 また、管理層の業務に限定しているので誤りである。 |
| イ | ○ | システム全体としての最適化のために、企業全体の業務が見渡せるような概略を作成し、そこから個々を細分化して全社データモデルを作成する。 |
| ウ | × | 全社のデータモデルは,業務層の現状システムを分析して作成するものではない。企業全体のあるべき姿から考えるものである。 また、業務層の業務に限定しているので誤りである。これでは、小手先の改善にとどまってしまう。 |
| エ | × | E-R モデルは,重要な処理を行っている業務に着目して作成するものではないし、業務はエンティティではなくプロセスである。 また、リレーションシップは、E-Rモデルで、エンティティ(実体)間の関係を表す。すなわち流れをリレーションシップとしてとらえるのではない。 |
お問い合わせ

