- トップページ
- 応用情報技術者
- 平成29年度秋季問題
- 平成29年度秋季解答・解説
平成29年度秋季解答
問題26
ストアドプロシージャの利点はどれか。
| ア | アプリケーションプログラムからネットワークを介してDBMSにアクセスする場合、両者間の通信量を減少させる。 |
| イ | アプリケーションプログラムから一連の要求を一括して処理することによって、DBMS内のアクセスパスの数を減少させる。 |
| ウ | アプリケーションプログラムからの一連の要求を一括して処理することによって、DBMS内の必要バッファ数を減少させる。 |
| エ | データが格納されているディスク装置へのI/O回数を減少させる。 |
解答:ア
<解説>
ストアドプロシージャ機能は、データベースに対する一連の処理手順を一つのプログラムにまとめ、データベース管理システムに保存したもの。通常のようにSQL文を一つずつ送るのに比べて、ネットワークのトラフィックを削減できる。また、サーバ上で構文解析や機械語への変換を前もって終わらせておくため、処理時間の軽減にもつながる。
したがって、アが正解である。
問題27
第3正規形であることの効果又は影響に関する記述として、適切なものはどれか。
| ア | 画面や帳票の行をそのままデータベースの行に対応させるので、データ量が増える。 |
| イ | 結合操作が不要となり、データベース全体の処理効率が向上する。 |
| ウ | 更新時のデッドロックを避けることができる。 |
| エ | 冗長性が排除され、データの整合性を保ちやすくなる。 |
解答:エ
<解説>
データの正規化とは,データの重複をなくすことにより,データの管理を容易にしたり,データを多様な目的に用いるのに有効な方法で,データベースの構築の基本になる技法である。
通常、正規化は第1正規形~第3正規形の3段階で行う。
- 第1正規化:繰り返し部分を別レコードとして分離し固定長レコードにする。
- 第2正規化:レコードの主キーに完全従属する属性と、主キーの一部分にのみ部分従属する属性を別のレコードとして分離させる。
- 第3正規化:主キー以外の属性に従属する属性を別レコードに分割する。
| ア | × | 画面や帳票の行をそのままデータベースの行に対応させることが第3正規化ではない。 |
| イ | × | 正規化によりデータが複数の表に分割されるので、結合操作は必要となる。 正規化はデータの整合性や柔軟性を向上させる一方で、データの取得の複雑化や処理速度の低下というデメリットも存在します。 |
| ウ | × | 更新時のデッドロックはトランザクションの処理順序の不備によって発生します。 |
| エ | ○ | 冗長性が排除され、データの整合性を保ちやすくなる。 |
問題28
関係R(ID, A, B, C)のA、Cへの射影の結果とSQL文で求めた結果が同じになるように、aに入れるべき字句はどれか。 ここで、関係Rを表Tで実現し、表Tに各行を格納したものを次に示す。
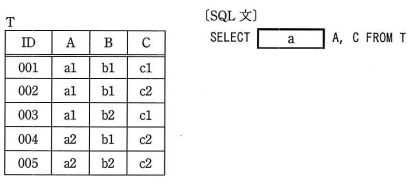
| ア | ALL |
| イ | DISTINCT |
| ウ | ORDER BY |
| エ | REFERENCES |
解答:イ
<解説>
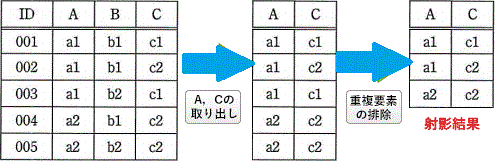
射影は、関係演算の1つで表の中から特定の列だけを取り出す操作であり、重複する行は排除される。
したがって、射影は、SQLのDISTINCTと同じである。DISTINCTを使用することで、SELECT文にて出力した実行結果の重複レコードを1つにまとめることができる。
問題29
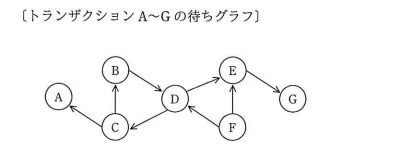
トランザクションA~Gの待ち行列において、永久待ちの状態になっているトランザクション全てを列挙したものはどれか。 ここで、待ちグラフのX →Y は、トランザクションX はトランザクションY がロックしている資源のアンロックを待っていることを表す。
| ア | A、B、C、D |
| イ | B、C、D |
| ウ | B、C、D、F |
| エ | C、D、E、F、G |
解答:ウ
<解説>
問題の待ちグラフではトランザクションB,C,Dの配置がが環状になっており,永久待ちの状態になります。
また,トランザクシ∋ンDが永久待ちになって資源を解放しなくなるので,その資漂のアンロックを待っているトランザクションFも,永久に待ち続ける状照になります。
よって,B,C,D,Fが適切です。
問題30
データマイニングの説明として、最も適切なものはどれか。
| ア | 基幹業務のデータベースとは別に作成され、更新処理をしない時系列データの分析を主目的とする。 |
| イ | 個人別データ、部門別データ、サマリデータなど、分析者の目的別に切り出され、カスタマイズされたデータを分析する。 |
| ウ | スライシング、ダイシング、ドリルダウンなどのインタラクティブな操作によって多次元分析を行い、意思決定を支援する。 |
| エ | ニューラルネットワークや総計解析などの手法を使って、大量に蓄積されているデータから、顧客購買行動の法則などを探し出す。 |
解答:エ
<解説>
データマイニングは、通常業務において発生した大量のデータを蓄積し、それらを統計解析・ニューラルネットワークなどの数学的手法を用いて分析して、データの中に隠れた法則や因果関係などを算出する方法です。
| ア | × | データウェアハウスの説明です。元となるデータベースはデータ分析に向いた構造になっているとは限らないので,データベースを再構築します。 |
| イ | × | データマートの説明です。小規模なデータウェアハウスの形態で,分析者のニーズに合わせて使いやすいレベルのデータベースを作成 して分析します。 |
| ウ | × | OLAPの説明です。スライシングやダイシング,ドリルダウンは,OLAPの基本的な分析 手法で,マウスなどによるインタラクティブな操作で,多次元分析を行います。 |
| エ | ○ | データマイニングの説明である。 |
お問い合わせ

