- トップページ
- 応用情報技術者
- 平成30年度秋季問題
- 平成30年度秋季解答・解説
平成30年度秋季解答
問題1
任意のオペランドに対するブール演算A の結果とブール演算B の結果が互いに否定の関係にあるとき、A はB の(又は、B はA の)相補演算であるという。 排他的論理和の相補演算はどれか。
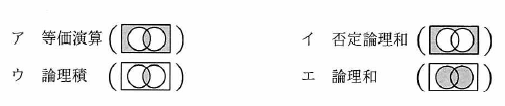
解答:ア
<解説>
排他的論理和とは、与えられた2つの命題のいずれかただ1つのみが真であるときに真となる論理演算である。
排他的論理和の演算結果,ベン図は次のようになる。
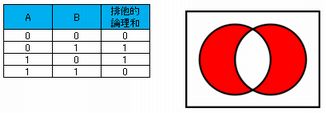
相補演算とは、否定の関係を示したものなのである。したがって、排他的論理和のベン図の否定なので、アが正解となる。
問題2
コンピュータによる伝票処理システムがある。 このシステムは、伝票データをためる待ち行列をもち、M/M/1の待ち行列モデルが適用できるものとする。 平均待ち時間がT 秒以上となるのは、処理装置の利用率が少なくとも何%以上となったときか。 ここで、伝票データをためる待ち行列の特徴は次のとおりである。
- 伝票データは、ポアソン分布にしたがって発生する。
- 伝票データのたまる数に制限はない。
- 1件の伝票データの処理時間は、平均T 秒の指数分布に従う。
| ア | 33 |
| イ | 50 |
| ウ | 67 |
| エ | 80 |
解答:イ
<解説>
- 処理装置の利用率をpとすると待ち行列の長さは、p/(1-p)で表すことができる。
平均待ち時間 (Tw)=待ちぎょうれうの長さ×平均処理時間(Ts)Tw = p Ts (1-p) - 平均回線待ち時間が平均伝送時間よりも最初に長くなるのはTwとTsが等しい場合のので、Tw=Ts=Tの時を考えると
T = p T (1-p) - 両辺をTで割ると次のようになる
1=p/(1-p)
1-p=p
2p=1
p=0.5 ∴50%
問題3
受験者1,000人の4教科のテスト結果は表のとおりであり、いずれの強化の得点分布も正規分布に従っていたとする。 90点以上の得点者が最も多かったと推定できる教科はどれか。
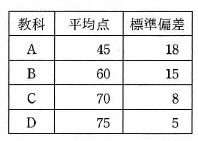
| ア | A |
| イ | B |
| ウ | C |
| エ | D |
解答:イ
<解説>
正規分布は,平均値の度数が最も高く. 平均値を中心にして左右対称に度数が低く なる分布(グラフ)のことである。
一般に,正規分布では,平均値土標準偏 差(α)の範囲にあるデータの数は,全体 のデータ数の約68%を占める。残りの 32%のうち、(平均値-標準偏差)未満の範囲となるデータが16%.(平均 値+標準偏差)以上の範囲となるデータが16%になる。同様に平均値土 2×標準偏差の範囲にあるデータ数は全体の数の約95%を占める。
平均点や標準偏差が異なる値の間で標準化をする場合,それぞれの平均点か らのずれを考え.(得点一平均点)÷標準偏差という値を求める。この値が 大きいほどその得点を取得した人が少なく、逆に小さいほどその得点を取得し た人が多いことになる。
したがって、90点の得点で計算すると次のようになる。
- A: (90-45) ÷18=2.5 ·
- B:(90-60)÷15=2 ·
- C:(90-70) ÷8=2.5 ·
- D:(90-75)÷5=3
この値が最も小さい教科が90点以上の得点者が多いと推定できるため,正解はイとなる。
問題4
次に示す記述は、BNFで表現されたあるプログラム言語の構文の一部である。 <パラメータ指定>として、正しいものはどれか。 <パラメータ指定> ::= <パラメータ> | (<パラメータ指定>, <パラメータ>) <パラメータ> ::= <英字> | <パラメータ><英字> <英字> ::= a | b | c | d | e | f | g | h | i
| ア | ((abc, def), ghi) |
| イ | ((abc, def)) |
| ウ | (abc, (def)) |
| エ | (abc) |
解答:ア
<解説>
解説省略
問題5
符号化方式に関する記述のうち、ハフマン符号はどれか。
| ア | 0と1の数字で構成する符号の中で、0又は1の連なりを一つのブロックとし、このブロックに長さを表す符号を割り当てる。 |
| イ | 10進数字の0~9を4ビット2進数の最初の10個に割り当てる。 |
| ウ | 発生確率がわかっている信号群を符号化したとき、1記号当たりの平均符号長が最小になるように割り当てる。 |
| エ | 連続した波を標本化と量子化によって0と1の数字で構成する符号に割り当てる。 |
解答:ウ
<解説>
ハフマン符号は、文字列を圧縮するための技法。
通常の符号化では、どの文字にも同じビット数(固定長のビット数)を割り当てますが、ハフマン符号では、出現頻度が少ない文字ほど長いビット数(逆に言うと、出現頻度が多い文字ほど短いビット数)に符号化する。 この符号化では、ハフマン木を使う。
したがって、イが正解である。
お問い合わせ

