- トップページ
- 応用情報技術者
- 平成29年度春季問題
- 平成29年度春季解答・解説
平成29年度春季解答
問題26
データモデルを解釈してオブジェクト図を作成した。 解釈の誤りを適切に指摘した記述はどれか。 ここで、モデルの表記にはUMLを用い、オブジェクト図の一部の属性の表示は省略した。
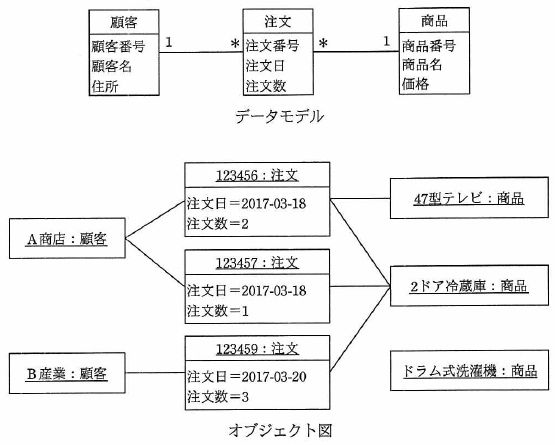
| ア | “123456:注文”が複数の商品にリンクしているのは、誤りである。 |
| イ | “2ドア冷蔵庫:商品”が複数の注文にリンクしているのは、誤りである。 |
| ウ | “A商店:顧客”が複数の注文にリンクしているのは、誤りである。 |
| エ | “ドラム式洗濯機:商品”がどの注文にもリンクしていないのは、誤りである。 |
解答:ア
<解説>
| ア | ○ | 「注文」には一つの商品しか含んではならない。 |
| イ | × | 「商品」は0個からN個の注文に含まれる場合がある。 |
| ウ | × | 「顧客」は0個からN個の注文を行うことができる。 |
| エ | × | 「商品」の注文がない(0個の)場合もある。 |
問題27
“受注明細”表は、どのレベルまでの正規形の条件を満足しているか。 ここで、実線の下線はは主キーを表す。
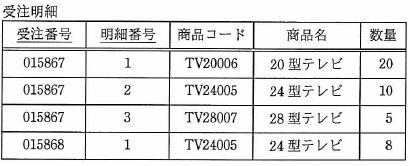
| ア | 第1正規形 |
| イ | 第2正規形 |
| ウ | 第3正規形 |
| エ | 第4正規形 |
解答:イ
<解説>
データの正規化とは,データの重複をなくすことにより,データの管理を容易にしたり,データを多様な目的に用いるのに有効な方法で,データベースの構築の基本になる技法である。
通常、正規化は第1正規形~第3正規形の3段階で行う。
- 第1正規化:繰り返し部分を別レコードとして分離し固定長レコードにする。
- 第2正規化:レコードの主キーに完全従属する属性と、主キーの一部分にのみ部分従属する属性を別のレコードとして分離させる。
- 第3正規化:主キー以外の属性に従属する属性を別レコードに分割する。
したがって、問題の"受注明細"表は次のようになる。
- 繰り返し部分が存在しないため、第1正規化の条件を満たしている。
- レコードの主キーに完全従属する属性と、主キーの一部分にのみ部分従属する属性を別のレコードとして分離させているため、第2正規化の条件も満たしている。
- 商品コードから商品名が一意に決まっているので互いに関係従属したままである。よって第3正規化の条件は満たしていない。
なお、第3正規系の条件を満たすと次のようになる。
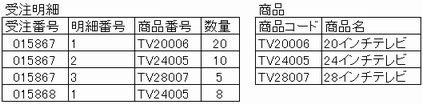
したがって、イが正解である。
問題28
“部品”表のメーカコード列に対し、B+木インデックスを作成した。これによって、検索の性能改善が最も期待できる操作はどれか。ここで、部品及びメーカのデータ件数は十分に多く、“部品”表に存在するメーカコード列の値の種類は十分な数があり、かつ、均一に分散されているものとする。また、“部品”表のごく少数の行には、メーカコード列にNULLが設定されている。実線の下線は主キーを、破線の下線は外部キーを表す。
部品(部品コード, 部品名, メーカコード)
メーカ(メーカコード, メーカ名, 住所)
| ア | メーカコードの値が1001以外の部品を検索する。 |
| イ | メーカコードの値が1001でも4001でもない部品を検索する。 |
| ウ | メーカコードの値が4001以上、4003以下の部品を検索する。 |
| エ | メーカコードの値がNULL以外の部品を検索する。 |
解答:ウ
<解説>
| ア | × | 「以外」を検索するためには、全数を線形検索する必要がある。したがって、1001以外を検索するのは非効率である。 |
| イ | × | 「以外」を検索するためには、全数を線形検索する必要がある。したがって、1001でも4001でもない部品を検索するのは非効率である。 |
| ウ | ○ | B+木インデックスでは、範囲を指定した検索が最も効率よく検索できる。 |
| エ | × | 「以外」を検索するためには、全数を線形検索する必要がある。したがって、NULL以外を検索するのは非効率である。 |
問題29
トランザクションAとBが、共通の資源であるテーブルaとbを表のように更新するとき、デッドロックとなるのはどの時点か。
ここで、表中の①~⑧は処理の実行順序を示す。また、ロックはテーブルの更新直前にテーブル単位で行い、アンロックはトランザクションの終了後に行うものとする。

| ア | ③ |
| イ | ④ |
| ウ | ⑤ |
| エ | ⑥ |
解答:エ
<解説>
問題の更新処理は次のようになる。

したがって、エ(⑥)が正解となる。
問題30
ビッグデータの利用におけるデータマイニングを説明したものはどれか。
| ア | 蓄積されたデータを分析し、単なる検索だけでは分からない隠れた規則や相関関係を見つけ出すこと |
| イ | データウェアハウスに格納されたデータの一部を、特定の用途や部門ように切り出して、データベースに格納すること |
| ウ | データ処理の対象となる情報を基に想定した、データの構造、意味及び操作の枠組みのこと |
| エ | データを複数のサーバに複製し、性能と可用性を向上させること |
解答:ア
<解説>
データマイニングとは、企業が収集する大量のデータを分析し、 有用なパターンやルールを発見し、マーケティング活動を支援する統計的手法やツールの集合体のことである。
| ア | ○ | データマイニングの説明である。 |
| イ | × | データマートの説明である。 |
| ウ | × | データディクショナリの説明である。 |
| エ | × | データベースクラスタの説明である。 |
お問い合わせ

